
【新智元导读】李飞飞的 World Labs 首个「空间智能」模型,刚刚诞生了!一张图生成一个 3D 世界,网友惊呼:太疯狂了,我们进入了下一轮革命,这就是视频游戏、电影的未来。
AI 生成 3D 世界成真了!
就在刚刚,AI 教母李飞飞创立的 World Labs 首次官宣「空间智能」模型,一张图,即可生成一个 3D 世界。
用李飞飞的话说,「无论怎样理论化这个想法,都很难用语言描述一张照片或一句话生成 3D 场景的互动体验。」
这是迈向空间智能的第一步。
 交互传送门:https://www.worldlabs.ai/blog#footnote1
交互传送门:https://www.worldlabs.ai/blog#footnote1
所有场景都能在浏览器中实时渲染,还能实现可控的相机效果、可调节的模拟景深。

未来,游戏 NPC 的虚拟世界可以随意切换,都是分分钟生成的事情。


英伟达高级研究科学家、李飞飞高徒 Jim Fan 总结道,「GenAI 正在创造越来越高维度的人类体验快照。Stable Diffusion 是 2D 快照;Sora 是 2D+时间维度的快照;而 World Labs 是 3D、完全沉浸式的快照」。

今年 4 月,李飞飞被曝出开始自创业,专注于空间智能,新公司私下融资直接晋升 10 亿美元独角兽。
直到 9 月,这家名为 World Lab 正式亮相,并在新一轮融资 2.3 亿美金,得到了 AI 大牛 Geoffrey Hinton、Jeff Dean、谷歌前 CEO Eric Schmidt 等人的鼎力支持。
 World Labs 创始人团队,左起依次为 Ben Mildenhall、Justin Johnson、Christoph Lassner 和李飞飞
World Labs 创始人团队,左起依次为 Ben Mildenhall、Justin Johnson、Christoph Lassner 和李飞飞
如今酝酿半年多,空间智能终见雏形。
网友们激动地表示,太疯狂了,我们即将迎来一个像是 80 年代、90 年代那样的革命。这将让许多人实现他们的创意,有望降低开发成本,帮助工作室的新知识产权更大胆冒险。
这就是视频游戏、电影的未来。
VR 从此有了更多可能性。
探索一个新世界
不论是 Midjourney、FLUX,还是 Runway、DreamMachine,我们熟知的大多数 GenAI 工具仅能制作图像/视频 2D 内容。
若是实现了在 3D 中生成,视频的控制性、一致性能得到极大的改善。
这也就意味着,制作电影、游戏、模拟器等其他物理世界的数字表现形式,将会发生翻天覆地的变化。
World Labs 成立开始的初衷便是,空间智能的 AI 对世界进行建模,还能 3D 时空中物体/地点/交互进行推理。
这次,他们首次展示了这个 3D 生成的世界。
如下,是在浏览器中进行的实时渲染演示(注:AI 图像均由 FLUX 1.1 pro/Ideogram/Midjourney 生成)。
输入一张 AI 生成的古色古香的村庄图像,然后就可以得到一个 3D 的世界。
 提示:这是一个古色古香的村庄,鹅卵石铺就的街道,茅草屋顶的小木屋,中央广场上有一口石井,周围是花坛
提示:这是一个古色古香的村庄,鹅卵石铺就的街道,茅草屋顶的小木屋,中央广场上有一口石井,周围是花坛

一座富丽堂皇的宫殿,AI 把光与影都展现得淋漓尽致。


一幅 AI 生成的折纸类图片,立刻活灵活现了起来。


又或者输入一张博物馆取景照片,谁又能想到这周围是什么样子的呢?

AI 帮你设想出了一切,出入门,下一间相邻的展馆、展品。....

再比如这张实景图,AI 也能想象出周围的世界。


相机效果
你还可以体现不同相机效果,场景生成后,会使用虚拟相机在浏览器中进行实时渲染。
通过对这个相机的精准控制,便可以实现艺术摄影特效。
比如模拟不同的景深,让只有在相机特定距离范围内的物体保持清晰:

还可以模拟滑动变焦(dolly zoom),通过同时调整相机的位置和视场角来实现这一效果:

3D 特效
大多数生成式模型都是预测像素的。而预测 3D 场景有很多好处:
- 场景持久性:一旦生成了一个世界,它就会稳定存在。即使你转开视线后再次观看,场景也不会在你看不见时发生变化。
- 实时控制:生成场景后,你可以在其中实时移动。你可以仔细观察花朵的细节,或是探头查看角落后面有什么。
- 几何精确性:这个生成的世界遵循基本的 3D 几何物理规则。它们具有真实的立体感和空间深度,与某些 AI 生成视频的虚幻效果形成鲜明对比。
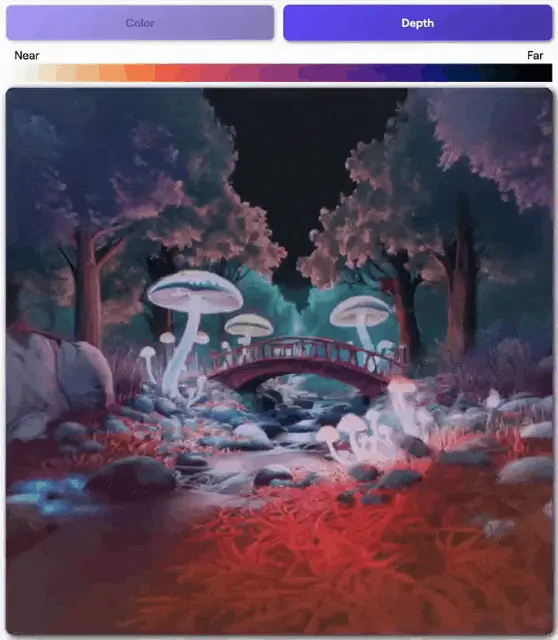
可视化 3D 场景最简单的方法是,就是使用深度图(depth map)。在深度图中,每个像素都会根据其到相机的距离来着色:

我们不仅可以利用 3D 场景结构来创建交互特效:


还可以创建自动运行的动态效果,为场景注入生命力:
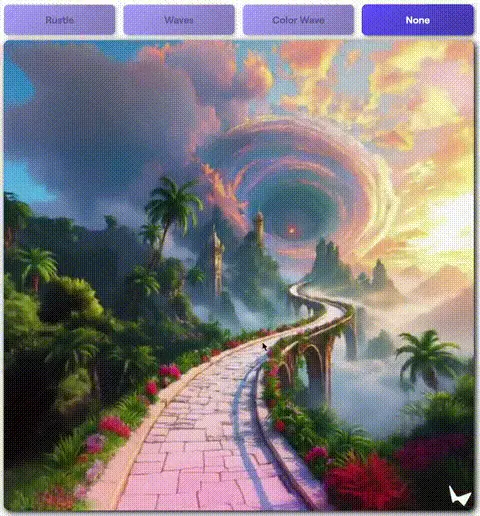
名画中的 3D 世界也可实时交互了。
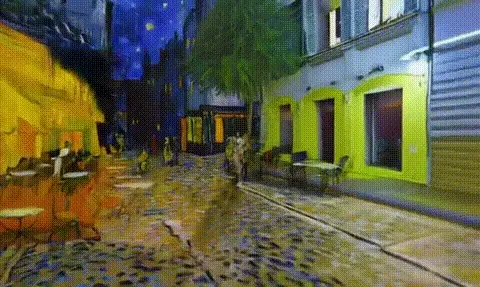
走进梵高的露天咖啡馆
现在,我们可以以全新的方式,体验标志性的艺术作品了!
原画中没有任何东西,是由模型生成的。
下面,就让我们走进从梵高、霍珀、修拉和康定斯基最喜欢的作品中生成的世界。

创意工作流
现在,3D 世界生成可以十分自然地和其他 AI 工具组合在一起,创作者们可以使用已知的工具,获得无比丝滑的全新体验了。
首先,可以通过使用文本到图像模型生成图像,来从文本创建世界。
不同的模型都有自己的不同风格,而空间智能世界可以继承这些风格。
下面就是使用不同的文本到图像模型生成同一场景的四个变体, 它们使用的都是相同的提示。
提示:一间充满朝气的动漫风格青少年卧室,床上铺着五颜六色的毯子,书桌上杂乱地摆着一台电脑,墙上贴满了海报,各种运动器材随意地散落在房间里。一把吉他斜靠在墙边,房间中央铺着一块带有精美图案的舒适地毯。窗外透进的阳光为整个房间营造出温馨活力的青春氛围。

现在,已经有一些创作者提前试用了。
比如 Eric Solorio 就使用这个模型,填补了自己创意工作流程中的空白,可以让场景中的角色可以上阵,甚至还能指导摄像机精确移动。
Brittani Natail 则将 World Labs 技术与 Midjourney、Runway、Suno、ElevenLabs、Blender 和 CapCut 等工具相结合,在生成的世界中精心设计了摄像机路径。
因此,得以在三部短片中唤起不同的情绪。
现在,候补名单已经开放了,话不多说了,赶快去申请吧。
空间智能,计算机视觉下一个前沿
此前,李飞飞在一次活动中,首次详细揭秘了何谓「空间智能」:
视觉化为洞察,看见成为理解,理解导致行动。
她将人类智能归结为两大智能,一是语言智能,另一个便是空间智能。虽然语言智能备受关注,但空间智能将对 AI 产生重大的影响。

而在 4 月公开的 TED 演讲中,李飞飞也分享了自己关于空间智能的更多思考,同时预示着 World Labs 的目标所在。
她表示,「所有空间智能的生物所具备的行动能力,是与生俱来的。因为,它能够将感知与行动进行关联」。
「如果想让 AI 超越其自身当前的能力,我们需要的是,不仅仅能够看到、会说话的 AI,而是一个可以行动的 AI」。

就连英伟达高级计算机科学家 Jim Fan 称,「空间智能,是计算机视觉和实体智能体的下一个前沿」。
正如 World Labs 的官博所阐述的那样,人类智能包含了诸多方面。
语言智能,可以让我们通过语言与他们进行交流和联系。而其中最为基础的便是——空间智能,能够让我们理解,并与周围世界进行互动。
此外,空间智能具备了极强的创造力,可以将我们脑海中的画面,在现实中呈现。
正是有了空间智能,人类能够推理、行动和发明。从简单的沙堡到高耸的城市可视化设计,都离不开它。

在接受彭博最新采访中,李飞飞表示,人类的空间智能,实际上经过了数百万年的演化而来。
这是一种理解、推理、生成,甚至在一个 3D 世界中互动的能力。不论是你观赏美丽的花朵,尝试触摸蝴蝶,还是建造一座城市,所有这些皆是空间智能的一部分。
不仅是人类,动物身上也可以看到这一点。

那么,如何让计算机也能具备空间智能的能力呢?其实我们已经取得了巨大的进步,过去十年 AI 领域的发展相当振奋人心。
一句提示,AI 生成图像、视频,真知还能讲述故事。这些模型已经以全新的方式,重塑人类的工作和生活方式。
而我们仅是看到了 GenAI 革命前夜的第一章。
下一步,如何超越?
需要将这些能力,如何带到 3D 领域。因为现实世界,就是 3D 的,同时人类空间智能是建立在非常「原生」的理解和操作 3D 的能力之上的。

如今,单个图像生成 3D 世界模型,让我们对空间智能有了初步的理解。
参考资料: