On December 20, OpenAI announced the launch of its next-generation model o3 and its streamlined version o3-mini on the last day of its 12-working day online new product launch event. o3 significantly surpasses its predecessor o1 in many aspects, excelling in software engineering, competitive mathematics, and the ability to master human PhD-level natural science knowledge. Especially in the ARC-AGI assessment, o3 achieved a score of 75.7% to 87.5%, exceeding the 85% threshold of human level.
 Image source: Visual China
Image source: Visual China
The next generation model of o1, o3
On Friday, December 20th, local time, on the last day of a 12-day online new product release event, OpenAI announced the “final masterpiece”: the next-generation model of o1, o3, and two versions will be launched from the beginning. A formal o3, and a relatively smaller streamlined version o3-mini.
OpenAI CEO Sam Altman mentioned in the live broadcast that OpenAI officially announced the launch of the official version of o1, the so-called full health o1, on the first day of this 12th event. On the last day of the event, o3 appeared again. The introduction of the inference model was echoed from beginning to end, which can be regarded as a kind of careful design.
Logically speaking, the next generation of o1 should be named o2. As for why the new model is called o3, it was previously reported that OpenAI is to avoid conflict with the British telecommunications service provider named O2. Altman also confirmed this, saying that out of respect for O2, the same name was not given.
During the live broadcast, Altman called o3 "a very, very smart model." OpenAi's evaluation results also show that o3 is significantly better than o1 in terms of software engineering, writing code, competitive mathematics, and mastering human doctoral level natural science knowledge. At the same time, tests show that o3 has made a breakthrough in OpenAI's goal of realizing general artificial intelligence (AGI), with the highest test results reaching human-like levels.
In September this year, OpenAI released the o1 preview version of o1, saying that o1 is the first large model with truly universal reasoning capabilities. Its core capability reasoning is on GPQA-diamond, a benchmark for testing professional knowledge in chemistry, physics and biology. has been fully reflected. According to OpenAI evaluation, o1 comprehensively surpassed human PhD experts in this test, with an accuracy rate of 78.3%, while human experts scored 69.7%.
o3’s evaluation performance
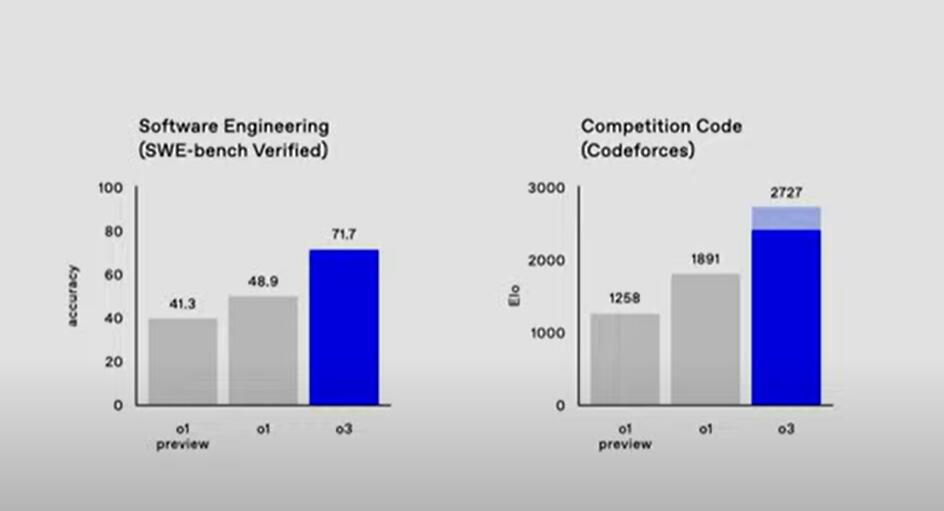
According to the SWE-bench Verified code generation evaluation benchmark launched by OpenAI in August, in the Software Engineering Capability Assessment, o3's accuracy score was 71.7, or the accuracy rate was 71.7%, far exceeding o1's score of 48.9 and o1's score of 41.3 preview. In other words, the accuracy of o3 is nearly 47% higher than the official version of o1 and nearly 74% higher than the o1 preview version.
In the Competitive Code Review from competitive programming website Codeforces, o3 achieved an Elo score of 2727, o1 scored 1891, and o1 preview scored 1258. The results of this evaluation show that in terms of competitive code, o3's score is 44% higher than the official version of o1, and more than twice that of the o1 preview version.
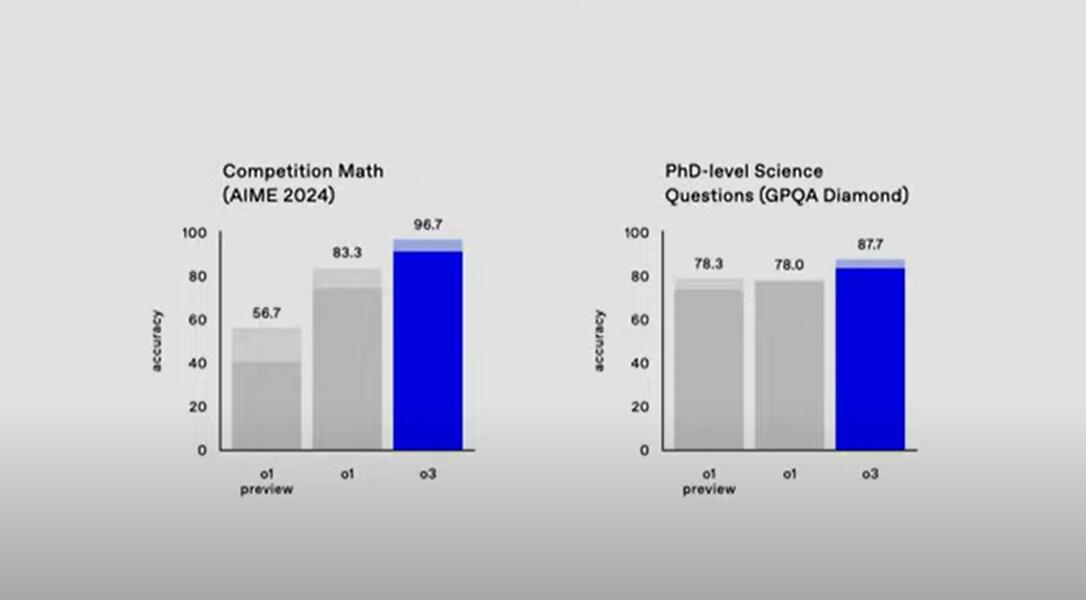
After the question test of the 2024 AIME Mathematics Competition, o3's accuracy score was 96.7, or the accuracy rate was 96.7%, which greatly exceeded the 56.7 of the o1 preview version and the 83.3% of o1. It only missed one question, which is quite a lot. At the level of a top mathematician. From a competition mathematics perspective, the accuracy of o3 is 15% higher than the official version of o1, and nearly 71% higher than the o1 preview version.
Tested by human PhD experts, on GPQA-diamond, a benchmark for testing professional knowledge in chemistry, physics and biology, o3's accuracy score is 87.7, that is, the accuracy rate is 87.7%, and o1 and o1 preview scored 78.0 respectively. and 78.3. The accuracy of o3 is nearly 13% higher than o1 and 12% higher than o1 preview.
o3’s reasoning ability
OpenAI also showed on Friday that o3's inference capabilities are getting closer to enabling AGI.
The ARC-AGI assessment results, with 100% as the highest score, show that o1 scored between 25% and 32%, while o3 had a minimum score of 75.7% and a maximum score of 87.5%. From this result, o3's best result exceeds the threshold of 85% that marks the achievement of human performance.
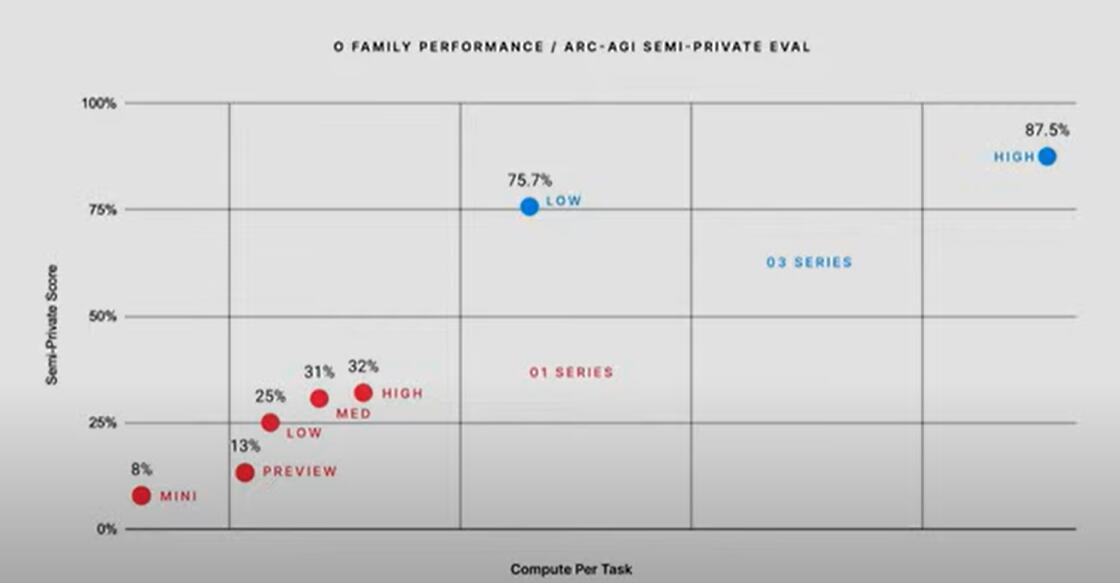
François Chollet, a former senior Google engineer and AI researcher who founded the ARC-AGI standard, said that the progress made by OpenAI's reasoning models in the AGI test is "robust."
Chollet posted on social media X on Friday, announcing the results of the ARC-AGI test conducted in collaboration with OpenAI, saying "We believe this represents a major breakthrough in adapting AI to new tasks."
o3-mini model
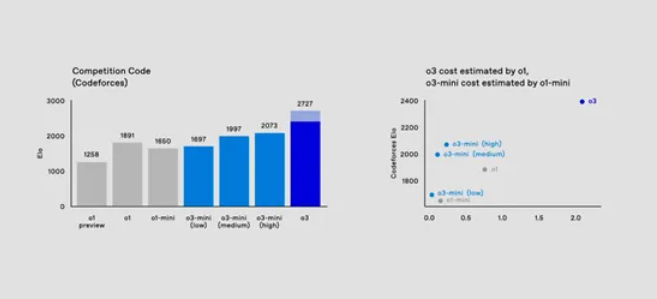
Compared with the o3 model, the o3-mini model performs well in terms of performance and cost balance, providing efficient services at a lower cost.
In terms of coding evaluation, the o3-mini model shows excellent performance improvements. In the CodeForces evaluation, as the thinking time increases, the performance of the o3-mini model continues to improve, gradually surpassing the o1-mini model.
At median think time, the o3-mini model even outperforms the o1 model, delivering comparable or even better code performance at approximately an order of magnitude lower cost. This means that developers can obtain more efficient programming assistance, improve development efficiency, and reduce development costs without increasing excessive costs.
In the math aptitude test, the o3-mini model performed well on the 2024 dataset. The performance of the o3-mini low model is comparable to that of o1-mini, while the o3-mini median model achieves better performance than o1. The o3-mini model can also show certain advantages when processing difficult data sets such as GPQA, achieving near-instant response.
In addition, the o3-mini model supports a series of functions such as function calls, structured output, and developer messages, which is equivalent to the O1 model. In practical applications, the o3-mini model achieves comparable or better performance in most evaluations.
During the live demonstration, the powerful features of the o3-mini model were visually demonstrated. For example, in one task, the model was asked to implement a code generator and executor using Python. When the Python script is started, the model successfully starts the local server and generates a user interface containing text boxes.
After the user enters a coding request in the text box, the model can quickly send the request to the API, automatically solve the task, generate the code and save it to the desktop, and then automatically open the terminal to execute the code. The entire process is complex and involves a lot of code processing, but the o3-mini model still shows extremely fast processing efficiency in low inference effort mode.
Release plan

Although o3's evaluation performance looks amazing, OpenAI should not launch this new super inference model to the public soon.
Starting December 20, OpenAI allows security researchers to register for preview access to o3 and o3-mini. An OpenAI spokesperson said that OpenAI plans to officially release these new o3 models early next year.