Since the release of DeepSeek-V3 and R1-Preview-Lite, which attracted the attention of the entire network, DeepSeek has released another blockbuster achievement.
On January 20, DeepSeek released a new open-source reasoning model DeepSeek-R1, which achieved a performance level comparable to OpenAI o1 in multiple tasks such as mathematics, programming and reasoning, while reducing the cost of calling the application programming interface (API) by 90-95%.
 Source: DeepSeek
Source: DeepSeek
More importantly, the experimental version of this model, DeepSeek-R1-Zero, proves that large models can also have powerful reasoning capabilities only through reinforcement learning (RL) and unsupervised fine-tuning (SFT).
NVIDIA senior research scientist Jim Fan commented: "We are living in a special era: a non-US company is truly practicing OpenAI's original mission - to conduct truly open cutting-edge research and empower everyone. This seems unreasonable, but the most dramatic is often the most likely to happen. DeepSeek-R1 not only open-sources a large number of models, but also discloses all training details.
They may be the first open source project to demonstrate the flywheel effect of reinforcement learning and achieve sustained growth. The demonstration of influence does not necessarily rely on mysterious names such as "ASI is realized internally" or "Strawberry Project". Sometimes directly disclosing the original algorithm and learning curve can also have a profound impact."
 Figure 丨 Related tweets (Source: X)
Figure 丨 Related tweets (Source: X)
Comparing with OpenAI o1 at 1/30 of the price
The performance evaluation results show that DeepSeek-R1-Zero trained by pure reinforcement learning methods and DeepSeek-R1 improved on this basis achieved 2024 AIME (American Mathematics Invitational Competition) test respectively. 71.0% and 79.8%, which is comparable to OpenAI o1's 79.2%.
In the MATH-500 benchmark, DeepSeek-R1 slightly surpassed o1's 96.4% with a score of 97.3%. In the field of programming, the model scored 2029 on the Codeforces platform, surpassing 96.3% of human programmers and only slightly behind o1-1217's score of 2061.
In terms of general knowledge assessment, DeepSeek-R1 also performed well. It achieved an accuracy of 90.8% in the MMLU (Massive Multi-Task Language Understanding) test, which is slightly lower than o1's 91.8%, but significantly better than other open source models.
It achieved an accuracy of 84.0% on MMLU-Pro and a pass rate of 71.5% in the GPQA Diamond test. In creative writing and question-answering tasks, the model achieved an 87.6% win rate in AlpacaEval 2.0 and a 92.3% win rate in ArenaHard.
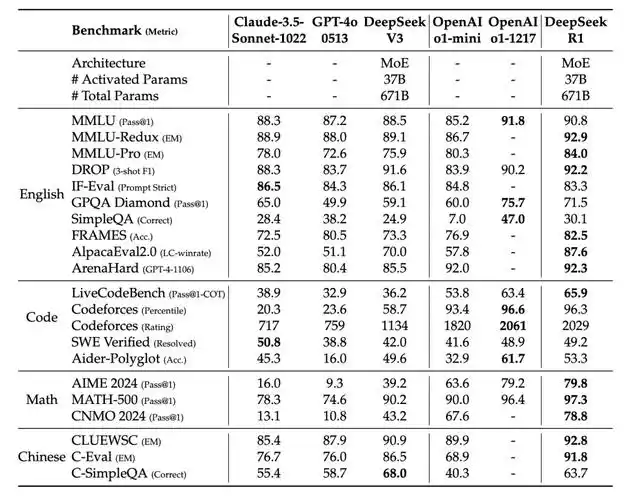 Figure 丨 Comparison of DeepSeek-R1 with other representative models (Source: DeepSeek)
Figure 丨 Comparison of DeepSeek-R1 with other representative models (Source: DeepSeek)
In terms of API pricing, DeepSeek has shown a strong cost-effectiveness advantage. Its API service charges $0.55/million for input tokens and $2.19/million for output tokens, while OpenAI o1 charges $15/million and $60/million respectively, with a price difference of nearly 30 times.
Pure reinforcement learning can achieve powerful reasoning capabilities
In addition to its outstanding performance, the development process of R1 also has many important innovations, the first of which is the breakthrough in pure reinforcement learning training strategy.
The traditional view is that a large amount of labeled data must be used for SFT before the model can have basic capabilities, and then RL can be used to improve capabilities. However, this DeepSeek study found that the largest model can rely entirely on reinforcement learning to obtain strong reasoning capabilities without any supervised fine-tuning. The research team first developed an experimental R1-Zero version. They chose to apply reinforcement learning directly on the DeepSeek-V3-base model, completely abandoning the traditional supervised fine-tuning link. This bold attempt produced amazing results: In the absence of manual labeled data, the model showed continuous self-evolution. Taking the AIME 2024 math test as an example, the model's pass@1 accuracy started from 15.6% at the beginning and continued to improve as the training progressed. Each round of reinforcement learning made the model smarter, and finally reached an accuracy of 71.0%. After using the majority voting mechanism, it was increased to 86.7%, which is close to the level of o1-0912.
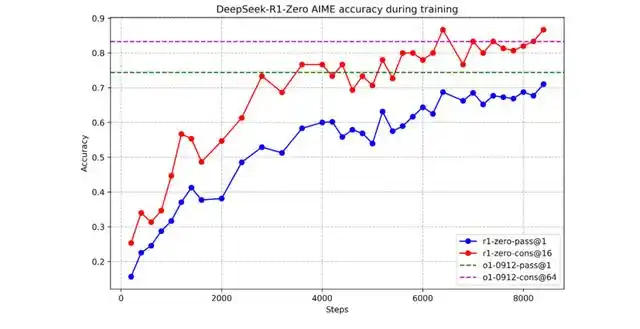 Figure 丨 AIME accuracy of DeepSeek-R1-Zero during training (Source: DeepSeek)
Figure 丨 AIME accuracy of DeepSeek-R1-Zero during training (Source: DeepSeek)
In this process, the researchers observed an interesting phenomenon: the model not only improved in numbers, but also made a qualitative leap in behavior patterns.
It began to show human-like thinking characteristics, actively reflecting on and verifying its own reasoning steps. When it was found that there might be problems with the current problem-solving ideas, the model would stop, re-examine the previous reasoning process, and then try to find a new solution.
This behavior was completely spontaneous, not achieved through artificial design. The researchers called this behavior the "aha moment" of the model. This shows that the model may have a certain degree of "metacognitive" ability, which can monitor and adjust its own thinking process.
 Figure 丨 An "aha moment" in the intermediate version of DeepSeek-R1-Zero (Source: DeepSeek)
Figure 丨 An "aha moment" in the intermediate version of DeepSeek-R1-Zero (Source: DeepSeek)
The core of these breakthroughs is the GRPO (Group Relative Policy Optimization) algorithm framework developed by the team. Traditional methods usually need to maintain a Critic network of the same size as the main model to estimate the state value, which not only increases the computational overhead, but also easily leads to training instability. GRPO takes a different approach, removing the large-scale Critic network and optimizing the policy network through group relative advantage estimation.
When dealing with an inference problem, the algorithm first samples multiple outputs {o1, o2, ..., oG} from the current policy πθold. These outputs together form a reference group, and then the policy model is optimized by maximizing the following objective, which is expressed as follows:
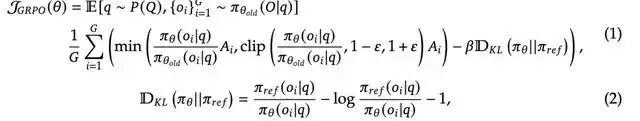
Where Ai represents the advantage value of output oi, which is calculated by normalizing the intra-group reward:
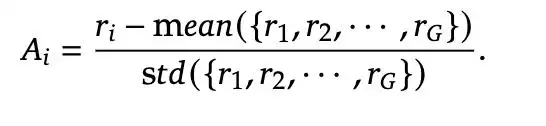
As for its reward mechanism, it contains three complementary components: accuracy reward to evaluate the correctness of the output, format reward to ensure the structure of the reasoning process, and reward signal to handle language consistency. These three rewards are combined with reasonable weights to jointly guide the model to evolve in the desired direction.
For example, in math problems, the accuracy reward comes from the verification result of the answer, while the format reward ensures that the model provides clear steps to solve the problem.
The training template provides a structured framework for the entire learning process. It adopts a two-stage design of "think-answer", requiring the model to first show the complete reasoning process in the <think> tag before giving the final answer in the <answer> tag.
This design not only makes the model's thinking process traceable, but also provides a clear evaluation benchmark for reward calculation. This template shows good adaptability whether dealing with mathematical reasoning or open-ended question answering.
These three components work closely together to build an effective learning system. Through the gradient estimation of the GRPO framework, the clear learning signal provided by the reward mechanism, and the structured output ensured by the training template, the model can continuously improve its reasoning ability and eventually reach the level close to that of human experts.
Reinforcement learning under cold start
Although R1-Zero has made breakthroughs in technology, it still has some problems. For example, DeepSeek-R1-Zero has limitations in poor readability and language mixing. To further improve the performance of the model, the research team continued to explore DeepSeek-R1 and developed a complete four-stage training process.
The first is the cold start stage. The team collected thousands of high-quality samples for preliminary fine-tuning. These samples come from a wide range of sources: some are obtained through few-shot prompts, containing detailed problem-solving ideas; some are from R1-Zero's high-quality output, which has been manually screened and annotated; and some are specially designed complex reasoning cases. The key to this stage is to ensure data quality rather than data quantity, laying a good foundation for subsequent reinforcement learning.
The second stage is reinforcement learning for reasoning. This stage inherits the training framework of R1-Zero, but has made important improvements. First, the language consistency reward is introduced. This design stems from a practical problem: in a multilingual environment, the model is prone to mix different languages in the reasoning process. This problem is effectively solved by calculating the proportion of target language words as a reward signal.
At the same time, the team made special optimizations for reasoning-intensive tasks. In mathematical problems, they designed a rule-based verification mechanism; in programming tasks, they used automated testing to evaluate code quality. These targeted optimizations significantly improved the performance of the model in professional fields.
The third stage is rejection sampling and supervised fine-tuning. The innovation of this stage is to use the trained RL model to generate new training data. The team adopted an important screening criterion: Only those samples that not only have correct answers but also clear reasoning processes are retained. This ensures the high quality of the data while maintaining the reasoning ability of the model.
At this stage, the scope of training has also expanded to a wider range of fields, including writing, question-answering, role-playing, etc. This expansion is not a simple task accumulation, but a carefully designed capability building process. The team found that general field training can in turn promote the reasoning ability of the model, forming a positive cycle.
The last stage is full-scenario reinforcement learning. The characteristic of this stage is the organic combination of different types of reward mechanisms: for structured tasks such as mathematics and programming, rule-based explicit rewards are used; for subjective tasks such as open-ended questions and answers and creative writing, model-based evaluation rewards are used. This flexible reward mechanism enables the model to improve the performance of general tasks while maintaining its reasoning ability.
Throughout the training process, the team also discovered an important phenomenon: The reasoning ability acquired by the large model through reinforcement learning has strong transferability. They used 800,000 training data generated by R1 to perform knowledge distillation on models of different sizes, and the results were surprising.
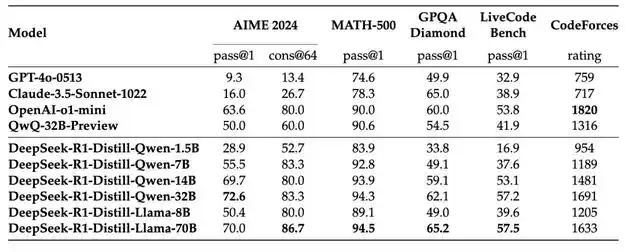 Figure 丨 Comparison of DeepSeek-R1 distillation model with other comparable models on reasoning-related benchmarks (Source: DeepSeek)
Figure 丨 Comparison of DeepSeek-R1 distillation model with other comparable models on reasoning-related benchmarks (Source: DeepSeek)
The smallest Qwen-1.5B model also achieved an accuracy of 28.9% on AIME, which has surpassed some much larger base models. The medium-sized Qwen-7B achieved an accuracy of 55.5%, which means that a model with only 7 billion parameters can solve quite complex mathematical problems.
Qwen-32B achieved an accuracy of 72.6% on AIME and 94.3% on MATH-500, both of which are close to the original R1 model. This discovery has important practical significance: it proves that we can effectively transfer the advanced capabilities of large models to smaller models through knowledge distillation, which provides a feasible path for the practical application of AI technology.
Currently, DeepSeek has fully open-sourced its models, including DeepSeek-R1-Zero, DeepSeek-R1, and six distillation models based on Qwen and Llama (with parameter sizes of 1.5B, 7B, 8B, 14B, 32B, and 70B respectively). These models are all published on the Hugging Face platform under the MIT License, and can be used for free commercial purposes, allowing for arbitrary modification and derivative development, and supporting secondary distillation training.