12 月 20 日,OpenAI 在其為期 12 個工作日的線上新品釋出活動最後一日宣佈推出下一代模型 o3 及其精簡版 o3-mini。o3 在多個方面顯著超越了其前代 o1,在軟體工程、競賽數學和掌握人類博士級別的自然科學知識能力等方面表現出色。尤其在 ARC-AGI 評估中,o3 的成績達到 75.7%至 87.5%,超過了人類水平的 85%門檻。
 圖片來源:視覺中國
圖片來源:視覺中國
o1 的下一代模型 o3
當地時間 12 月 20 日週五,在為期 12 個工作日的線上新品釋出活動最後一日,OpenAI 宣佈了“壓軸大作”:o1 的下一代模型 o3,而且一開始就要推出兩個版本,一個正式的 o3,還有一個相對較小的精簡版 o3-mini。
OpenAI 的 CEO Sam Altman 在直播中提到,OpenAI 本次 12 日的活動第一天官宣了上線正式版 o1、所謂滿血 o1。活動最後一天又有 o3 亮相,首尾都由介紹推理模型呼應,也算是一種精心設計。
邏輯上說,o1 的下一代應該命名為 o2,至於為什麼新模型叫 o3,之前報道稱,OpenAI 是為了避免和名為 O2 的英國電信服務商衝突。Altman 也確認了這點,說出於對 O2 的尊敬,並沒有起同樣的名字。
直播中,Altman 稱 o3 是“一個非常、非常聰明的模型”。OpenAi 的評估結果也顯示,無論在軟體工程、編寫程式碼,還是競賽數學、掌握人類博士級別的自然科學知識能力方面,o3 都明顯高出 o1 一籌。同時測試顯示,o3 在 OpenAI 實現通用人工智慧(AGI)這一奮鬥目標上取得了突破,最高的測試成績達到了類人水平。
今年 9 月,OpenAI 釋出 o1 的預覽版 o1 preview 時稱,o1 是第一個具備真正通用推理能力的大模型,它的核心能力推理在測試化學、物理和生物學專業知識的基準 GPQA-diamond 上得到了充分體現。據 OpenAI 評估,o1 在該測試中全面超過了人類博士專家,準確率達到 78.3%,而人類專家的得分為 69.7%。
o3 的測評表現
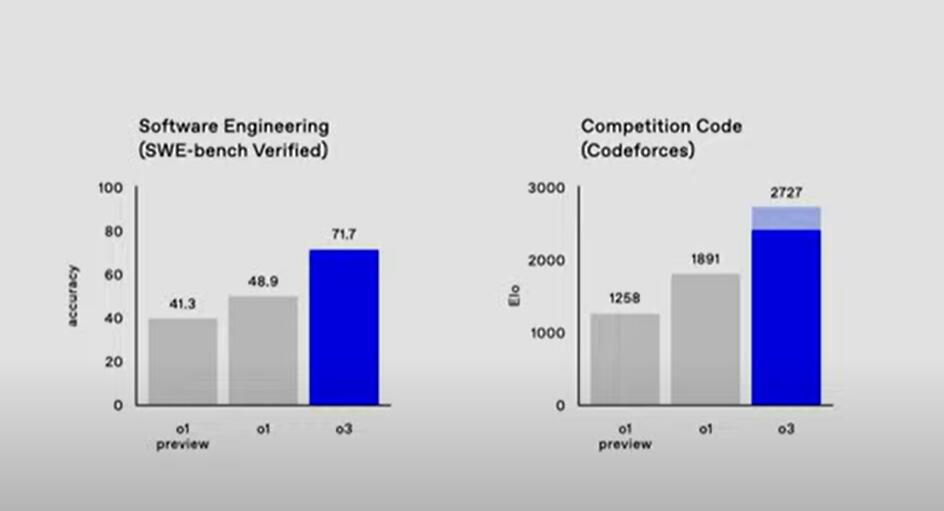
根據 OpenAI8 月推出的 SWE-bench Verified 程式碼生成評估基準,在軟體工程的能力測評中,o3 的準確度得分 71.7,即準確率 71.7%,遠超得分 48.9 的 o1 和得分 41.3 的 o1 preview。也就是說,o3 的準確率比 o1 正式版高將近 47%,比 o1 預覽版高將近 74%。
在競爭性程式設計網站 Codeforces 的競爭性程式碼測評中,o3 取得 2727 的 Elo 評分,o1 評分 1891,o1 preview 評分 1258。這個測評結果顯示,競爭性程式碼方面,o3 的評分比 o1 正式版高 44%,是 o1 預覽版的兩倍多。
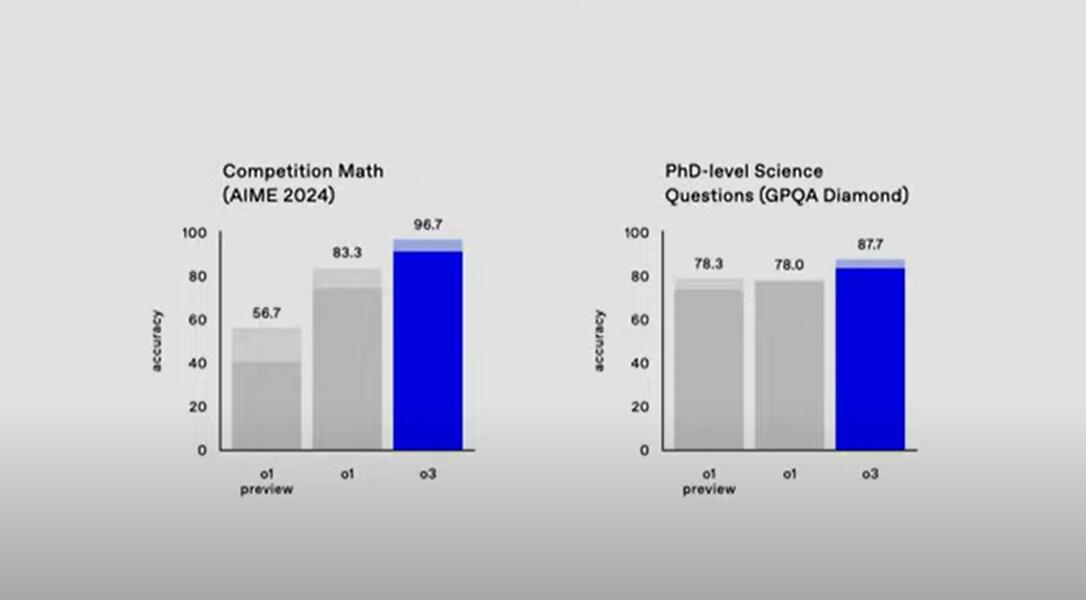
經過 2024 年 AIME 數學競賽的題目測試,o3 的準確度得分為 96.7、即準確率 96.7%,大幅度超過了 o1 預覽版的 56.7 和 o1 的 83.3%,僅錯了一道題,相當於一名頂級數學家的水平。從競賽數學的角度看,o3 的準確率比 o1 正式版高 15%,比 o1 預覽版高近 71%。
以人類博士專家的測試考驗,在測試化學、物理和生物學專業知識的基準 GPQA-diamond 上,o3 的準確度得分為 87.7,即準確率 87.7%,o1 和 o1 preview 分別得分 78.0 和 78.3。o3 的準確率比 o1 高將近 13%,比 o1 預覽版高 12%。
o3 的推理能力
OpenAI 週五還展示了,o3 的推理能力已經更加接近實現 AGI。
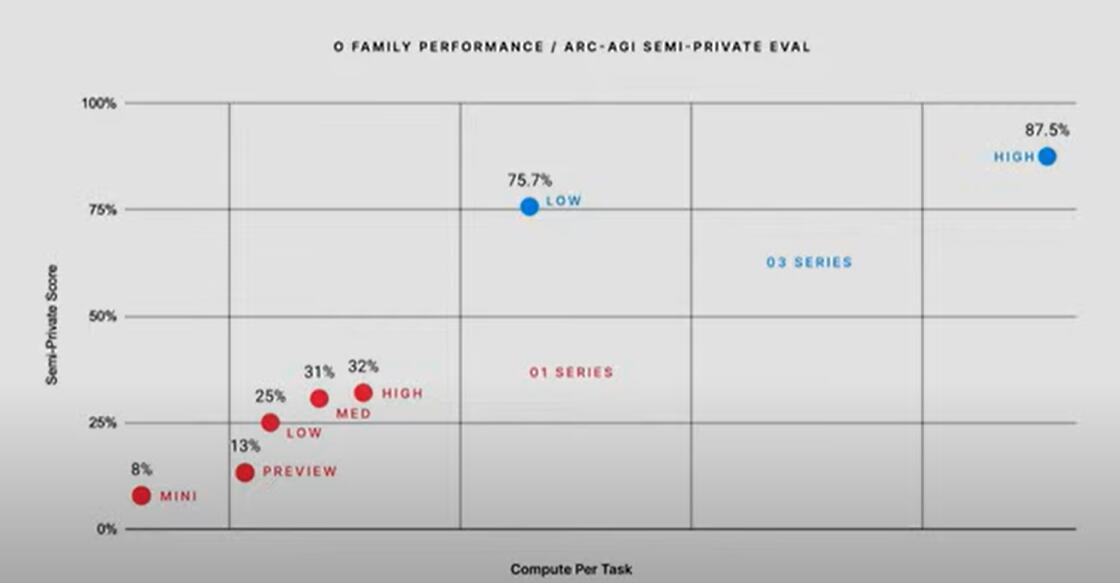
以 100%為最高分的 ARC-AGI 評估結果顯示,o1 的得分在 25%到 32%,而 o3 的最低成績為 75.7%,最高成績為 87.5%。從這個結果看,o3 的最佳成績超過了標誌著達到人類水平的門檻 85%。
創始 ARC-AGI 標準的前谷歌高階工程師、AI 研究員 François Chollet 表示,OpenAI 這些推理模型在 AGI 測試中取得進步是“穩健的”。
Chollet 週五在社交媒體 X 發帖,公佈了同 OpenAI 合作進行的 ARC-AGI 測試結果,稱“我們相信這代表了讓 AI 適應新任務的重大突破。”
o3-mini 模型
與 o3 模型相比,o3-mini 模型在效能與成本平衡方面表現出色,能夠以較低的成本提供高效的服務。
在編碼評估方面,o3-mini 模型展現出了出色的效能提升。在 CodeForces 的評估中,隨著思考時間的增加,o3-mini 模型的表現不斷提升,逐漸超越了 o1-mini 模型。
在中位思考時間下,o3-mini 模型的效能甚至優於 o1 模型,能夠以大約一個數量級的更低成本提供相當甚至更好的程式碼效能。這意味著開發人員可以在不增加過多成本的情況下,獲得更高效的程式設計輔助,提高開發效率,降低開發成本。
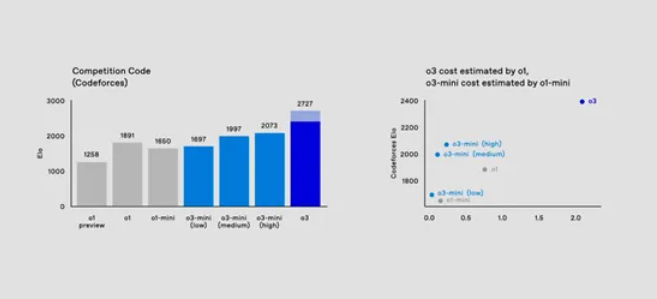
在數學能力測試中,o3-mini 模型在 2024 年資料集上表現出色。o3-mini 低模型的效能與 o1-mini 相當,而 o3-mini 中位數模型則取得了比 o1 更好的效能。在處理諸如 GPQA 等困難資料集時,o3-mini 模型也能展現出一定的優勢,實現了接近即時響應的效果。
此外,o3-mini 模型支援函數呼叫、結構化輸出、開發者訊息等一系列功能,與 O1 模型相當。在實際應用中,o3-mini 模型在大多數評估中實現了可比或更好的效能。
在現場演示中,o3-mini 模型的強大功能得到了直觀展示。例如,在一項任務中,模型被要求使用 Python 實現一個程式碼生成器和執行器。當啟動執行該 Python 指令碼後,模型成功啟動了本地伺服器,並生成了包含文字框的使用者介面。
使用者在文字框中輸入編碼請求後,模型能夠迅速將請求傳送至 API,並自動解決任務,生成程式碼並儲存至桌面,隨後自動開啟終端執行程式碼。整個過程複雜且涉及大量程式碼處理,但 o3-mini 模型在低推理努力模式下依然表現出了極快的處理效率。
釋出計劃

雖然 o3 的測評看上去表現驚豔,但 OpenAI 應該不會很快面向大眾上線這款新的超級推理模型。
從 12 月 20 日開始,OpenAI 允許安全研究人員可以註冊訪問 o3 和 o3-mini 的預覽。OpenAI 的一名發言人稱,OpenAI 計劃明年初正式釋出這些新的 o3 模型。