自此前釋出了 DeepSeek-V3 和 R1-Preview-Lite 引發全閘道器注之後,DeepSeek 又釋出了一項重磅成果。
1 月 20 日,DeepSeek 釋出了全新的開源推理大模型 DeepSeek-R1,在數學、程式設計和推理等多個任務上達到了與 OpenAI o1 相當的表現水平,同時將應用程式程式設計介面(API,Application Programming Interface)呼叫成本降低了 90-95%。
 (來源:DeepSeek)
(來源:DeepSeek)
更重要的是,這一模型的實驗性版本 DeepSeek-R1-Zero 證明了僅通過強化學習(RL,Reinforcement Learning),無監督式微調(SFT,Supervised Fine-Tun-ing),大模型也可以有強大的推理能力。
英偉達高階研究科學家 Jim Fan 評價道:“我們正生活在一個特殊的時代:一家非美國公司在真正踐行著 OpenAI 最初的使命——開展真正開放的前沿研究,為所有人賦能。這看似不合常理,但最富戲劇性的往往最可能發生。DeepSeek-R1 不僅開源了大量模型,還公開了所有訓練細節。
他們可能是首個展示出強化學習飛輪效應,並實現持續增長的開源項目。影響力的展現不一定要靠‘內部實現了 ASI’或‘草莓計劃’這樣神祕的名號,有時候直接公開原始演算法和學習曲線同樣可以產生深遠影響。”
 圖丨相關推文(來源:X)
圖丨相關推文(來源:X)
用 1/30 的價格比肩 OpenAI o1
效能評估結果顯示,通過純強化學習方法訓練得到的 DeepSeek-R1-Zero 以及在此基礎上改進的 DeepSeek-R1,在 2024 年 AIME(美國數學邀請賽)測試中分別取得了 71.0% 和 79.8% 的成績,與 OpenAI o1 的 79.2% 水平相當。
在 MATH-500 基準測試中,DeepSeek-R1 更是以 97.3% 的成績略微超越了 o1 的 96.4%。在程式設計領域,該模型在 Codeforces 平臺上獲得了 2029 的評分,超過了 96.3% 的人類程式設計師,與 o1-1217 的 2061 評分僅有小幅差距。
在通用知識評測方面,DeepSeek-R1 同樣表現出色。在 MMLU(大規模多工語言理解)測試中達到 90.8% 的準確率,雖然略低於 o1 的 91.8%,但顯著優於其他開源模型。
在 MMLU-Pro 上取得 84.0% 的準確率,在 GPQA Diamond 測試中達到 71.5% 的通過率。在創意寫作和問答任務上,模型在 AlpacaEval 2.0 中獲得了 87.6% 的控長勝率,在 ArenaHard 評測中達到 92.3% 的勝率。
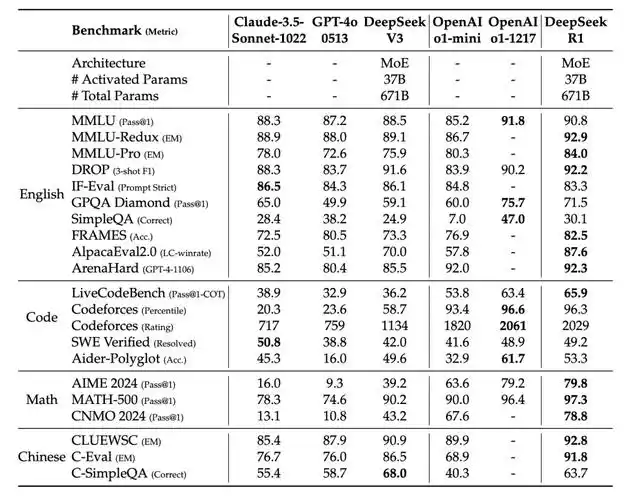 圖丨 DeepSeek-R1 與其他代表性模型的比較(來源:DeepSeek)
圖丨 DeepSeek-R1 與其他代表性模型的比較(來源:DeepSeek)
在 API 定價方面,DeepSeek 展現出極強的價效比優勢。其 API 服務對輸入 token 收取 0.55 美元/百萬,輸出 token 收取 2.19 美元/百萬,而 OpenAI o1 的收費分別為 15 美元/百萬和 60 美元/百萬,價格差距接近 30 倍。
純強化學習就能實現強大的推理能力
除了效能方面的出色,R1 的開發過程也具有多處重要創新,首先是純強化學習訓練策略的突破。
傳統觀點認為,必須先通過大量標註資料進行 SFT,才能讓模型具備基礎能力,之後才考慮使用 RL 進行能力提升。然而 DeepSeek 這項研究發現,大模型可以完全依靠強化學習獲得強大的推理能力,無需任何監督式微調。
研究團隊首先開發了實驗性的 R1-Zero 版本。他們選擇直接在 DeepSeek-V3-base 模型上應用強化學習,完全拋開了傳統的監督式微調環節。這個大膽的嘗試產生了驚人的效果:在完全沒有人工標註資料的情況下,模型展現出了持續的自我進化能力。
以 AIME 2024 數學測試為例,模型的 pass@1 準確率從最初的 15.6% 開始,隨著訓練的深入不斷提升。
每一輪強化學習都讓模型變得更加智慧,最終達到了 71.0% 的準確率,使用多數投票(majority voting)機制後更是提升至 86.7%,已經接近 o1-0912 的水平。
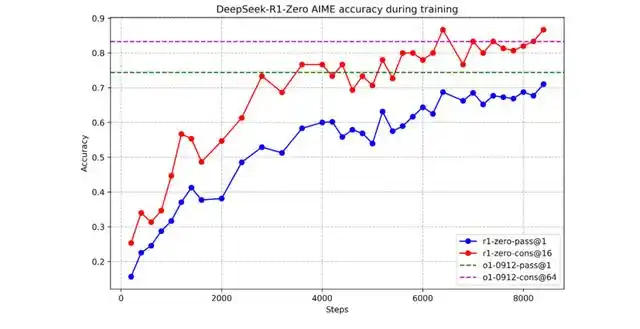 圖丨 DeepSeek-R1-Zero 在訓練期間的 AIME 準確率(來源:DeepSeek)
圖丨 DeepSeek-R1-Zero 在訓練期間的 AIME 準確率(來源:DeepSeek)
在這個過程中,研究人員觀察到了一個有趣的現象:模型不僅在數字上有進步,更在行為模式上發生了質的飛躍。
它開始表現出類似人類的思維特徵,會主動反思和驗證自己的推理步驟。當發現當前的解題思路可能存在問題時,模型會停下來,重新審視之前的推理過程,然後嘗試尋找新的解決方案。
這種行為完全是自發產生的,而不是通過人工設計實現的,研究人員將這一行為稱之為模型的“頓悟時刻”(aha moment)。這表明模型可能已經具備了某種程度的“元認知”能力,能夠對自身的思維過程進行監控和調整。
 圖丨 DeepSeek-R1-Zero 中間版本的一個“頓悟時刻”(來源:DeepSeek)
圖丨 DeepSeek-R1-Zero 中間版本的一個“頓悟時刻”(來源:DeepSeek)
支撐這些突破的核心是團隊開發的 GRPO(Group Relative Policy Optimization)演算法框架。傳統方法通常需要維護一個與主模型規模相當的 Critic 網路來估計狀態值,這不僅增加了計算開銷,還容易導致訓練不穩定。而 GRPO 則另闢蹊徑,移除了規模龐大的 Critic 網路,通過群組相對優勢估計來優化策略網路。
當處理一個推理問題時,演算法首先從當前策略 πθold 中取樣多個輸出 {o1, o2, ..., oG}。這些輸出共同構成一個參考組,然後通過最大化以下目標來優化策略模型,其表達如下:
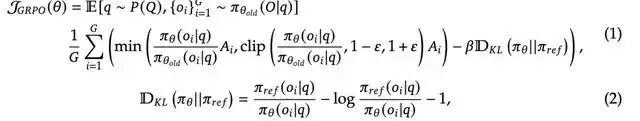
其中 Ai 表示輸出 oi 的優勢值,通過歸一化組內獎勵計算得到:
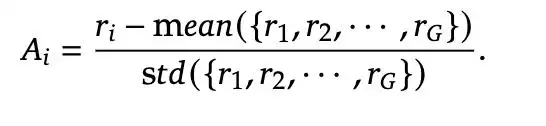
至於其獎勵機制則包含三個互補的元件:評估輸出正確性的準確性獎勵、確保推理過程結構化的格式獎勵,以及處理語言一致性的獎勵訊號。這三種獎勵通過合理的權重組合,共同指導模型向著期望的方向演進。
例如,在數學問題中,準確性獎勵來自答案的驗證結果,而格式獎勵則確保模型提供清晰的解題步驟。
訓練模板則為整個學習過程提供了結構化的框架。它採用“思考-回答”的雙階段設計,要求模型首先在<think>標籤中展示完整的推理過程,然後才能在<answer>標籤中給出最終答案。
這種設計不僅使模型的思維過程變得可追蹤,還為獎勵計算提供了明確的評估基準。無論是處理數學推理還是開放性問答,這個模板都展現出了良好的適應性。
這三個組成部分緊密配合,共同構建了一個有效的學習系統。通過 GRPO 框架的梯度估計,由獎勵機制提供的清晰學習訊號,以及訓練模板確保的結構化輸出,模型能夠持續提升其推理能力,最終達到接近人類專家的水平。
冷啟動下的強化學習
儘管 R1-Zero 在技術上取得了突破性進展,但它還存在一些問題,例如,DeepSeek-R1-Zero 在可讀性差和語言混合方面存在侷限。為了進一步提升模型效能,研究團隊繼續探索了 DeepSeek-R1,開發出一個完整的四階段訓練流程。
首先是冷啟動階段。團隊收集了數千個高質量樣本用於初步微調,這些樣本來源廣泛:一部分通過 few-shot 提示獲取,包含詳細的解題思路;另一部分來自 R1-Zero 的優質輸出,經過人工篩選和標註;還有一部分是專門設計的複雜推理案例。這個階段的關鍵是確保資料質量而不是資料量,為後續的強化學習奠定良好基礎。
第二階段是面向推理的強化學習。這個階段繼承了 R1-Zero 的訓練框架,但做了重要改進。首先是引入了語言一致性獎勵,這個設計源於一個實際問題:在多語言環境下,模型容易在推理過程中混用不同語言。通過計算目標語言單詞的比例作為獎勵訊號,有效地解決了這個問題。
同時,團隊對推理密集型任務進行了特別優化。在數學問題中,他們設計了基於規則的驗證機制;在程式設計任務中,則使用自動化測試來評估程式碼質量。這些針對性的優化顯著提升了模型在專業領域的表現。
第三階段是拒絕取樣與監督微調。這個階段的創新之處在於使用已訓練的 RL 模型來生成新的訓練資料。團隊採用了一個重要的篩選標準:只保留那些不僅答案正確,而且推理過程清晰的樣本。這確保了資料的高質量,同時也保持了模型的推理能力。
在這個階段,訓練範圍也擴充套件到了更廣泛的領域,包括寫作、問答、角色扮演等。這種擴充套件不是簡單的任務堆積,而是經過精心設計的能力構建過程。團隊發現,通用領域的訓練能夠反過來促進模型的推理能力,形成正向迴圈。
最後一個階段是全場景強化學習。這個階段的特點是將不同類型的獎勵機制有機結合:對於數學、程式設計等結構化任務,使用基於規則的明確獎勵;對於開放式問答、創意寫作等主觀任務,則採用基於模型的評估獎勵。這種靈活的獎勵機制使模型能夠在保持推理能力的同時,提升通用任務的表現。
在整個訓練過程中,團隊還發現了一個重要現象:**大模型通過強化學習獲得的推理能力具有強大的可遷移性。**他們使用 R1 生成的 80 萬條訓練資料對不同規模的模型進行知識蒸餾,結果令人意外。
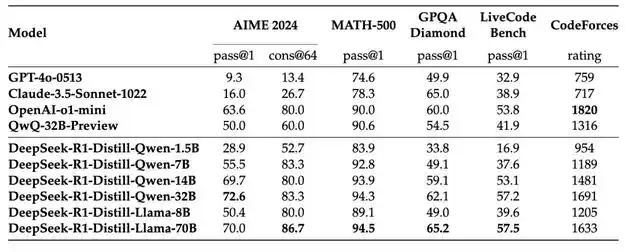 圖丨 DeepSeek-R1 蒸餾模型與其他可比模型在推理相關基準上的比較(來源:DeepSeek)
圖丨 DeepSeek-R1 蒸餾模型與其他可比模型在推理相關基準上的比較(來源:DeepSeek)
**最小的 Qwen-1.5B 模型在 AIME 上也達到了 28.9% 的準確率,這個成績已經超過了一些大得多的基礎模型。**中等規模的 Qwen-7B 達到了 55.5% 的準確率,這意味著一個僅有 70 億參數的模型就能解決相當複雜的數學問題。
而 Qwen-32B 在 AIME 上更是達到了 72.6% 的準確率,在 MATH-500 上達到了 94.3%,這些成績都接近於原始的 R1 模型。這一發現具有重要的實踐意義:它證明了我們可以通過知識蒸餾的方式,將大模型的高階能力有效地轉移到更小的模型中,這為 AI 技術的實際應用提供了一條可行的路徑。
目前,DeepSeek 已將模型完整開源,包括 DeepSeek-R1-Zero、DeepSeek-R1 以及基於 Qwen 和 Llama 的六個蒸餾模型(參數規模分別為 1.5B、7B、8B、14B、32B 和 70B)。這些模型均採用 MIT 許可(MIT License)釋出在 Hugging Face 平臺上,可以免費商用、允許任意修改和衍生開發、支援進行二次蒸餾訓練。